| channel | count_by_channel |
|---|---|
| SABC News | 7 |
| eNCA | 6 |
| Newzroom Afrika | 4 |
| Renaldo Gouws | 2 |
| Zenobia | 2 |
| emzi info | 2 |
| Al Jazeera English | 1 |
| Ayanda Mafuyeka | 1 |
| Azana Jezile | 1 |
| Beauty recipes | 1 |
| Buhle N | 1 |
| Clicks South Africa | 1 |
| Duke University - The Fuqua School of Business | 1 |
| Economic Freedom Fighters | 1 |
| Fresh Trendz | 1 |
| Havoc Mckush | 1 |
| Hot Mzansi | 1 |
| ITV News | 1 |
| Ile Eko Omoluabi | 1 |
| Jade Godbolt | 1 |
| Jamaal Curry | 1 |
| Justine South Africa Official | 1 |
| King Mshotinarry | 1 |
| Mama Shirat | 1 |
| Morexskinglow | 1 |
| Mzansi Hotspot | 1 |
| Newcastle Advertiser | 1 |
| NewsLiteSA | 1 |
| Owamie Entertainment | 1 |
| Prophet Pastor Ran | 1 |
| Rich SA | 1 |
| Shiro | 1 |
| StellenboschNews Com | 1 |
| The Brother Leader | 1 |
| The Hottest Scoop | 1 |
| TheKingzRSA | 1 |
| TimesLIVE Video | 1 |
| Tshepo Matseba APR | 1 |
| Tshidi Radebe | 1 |
| VIRAL VIDZ RSA | 1 |
Computational approaches in discourse analysis II
Marion Walton
Outline
- What is discourse?
- Computational linguistics overview
- Discourse analysis & Corpus linguistics
- Automating content analysis in Media studies
- Multimodal discourses
Quiz
- Multiple Choice Questions
- Take-home, Randomized
Question types:
- Based on readings
- Use Wordtree and Voyant tools to answer questions about Mandela speech and Clicks Corpus.
- Apply concepts from readings to examples from Clicks corpus
From readings

Multiple choice question
Using Wordtree

Ordering question
Lecture 2 - Beyond frequency
Meanings are contextual
Need to go beyond simply counting frequencies.
Context plays an important role in meaning.
For discourse analysis, frequent clusters of words are more revealing than just looking at individual words in isolation
Concepts
- Collocation
- Concordances
- Keyness
Social media corpus
200 posts were selected from results returned by the YouTube API in response to the following query: “Query: clicks south africa* hair (ad OR advertisement) -click” covering videos posted during the period 2020 - 2023
Posts were selected if they:
- Related directly to the controversy, or
- Related to issues about body politics and racism
A random sample (n=60) was selected for discourse analysis.
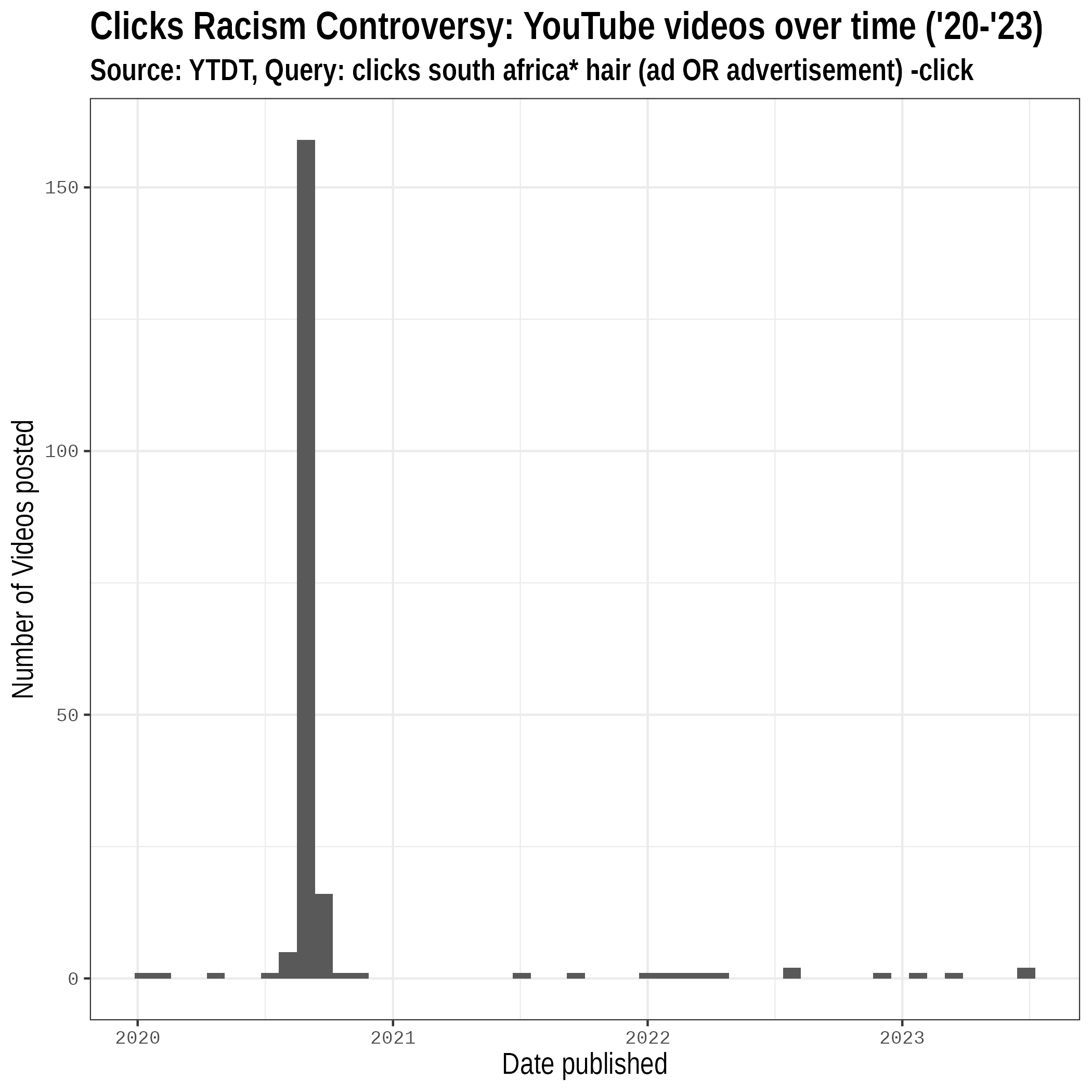
YouTube videos over time
Most Prolific Channels
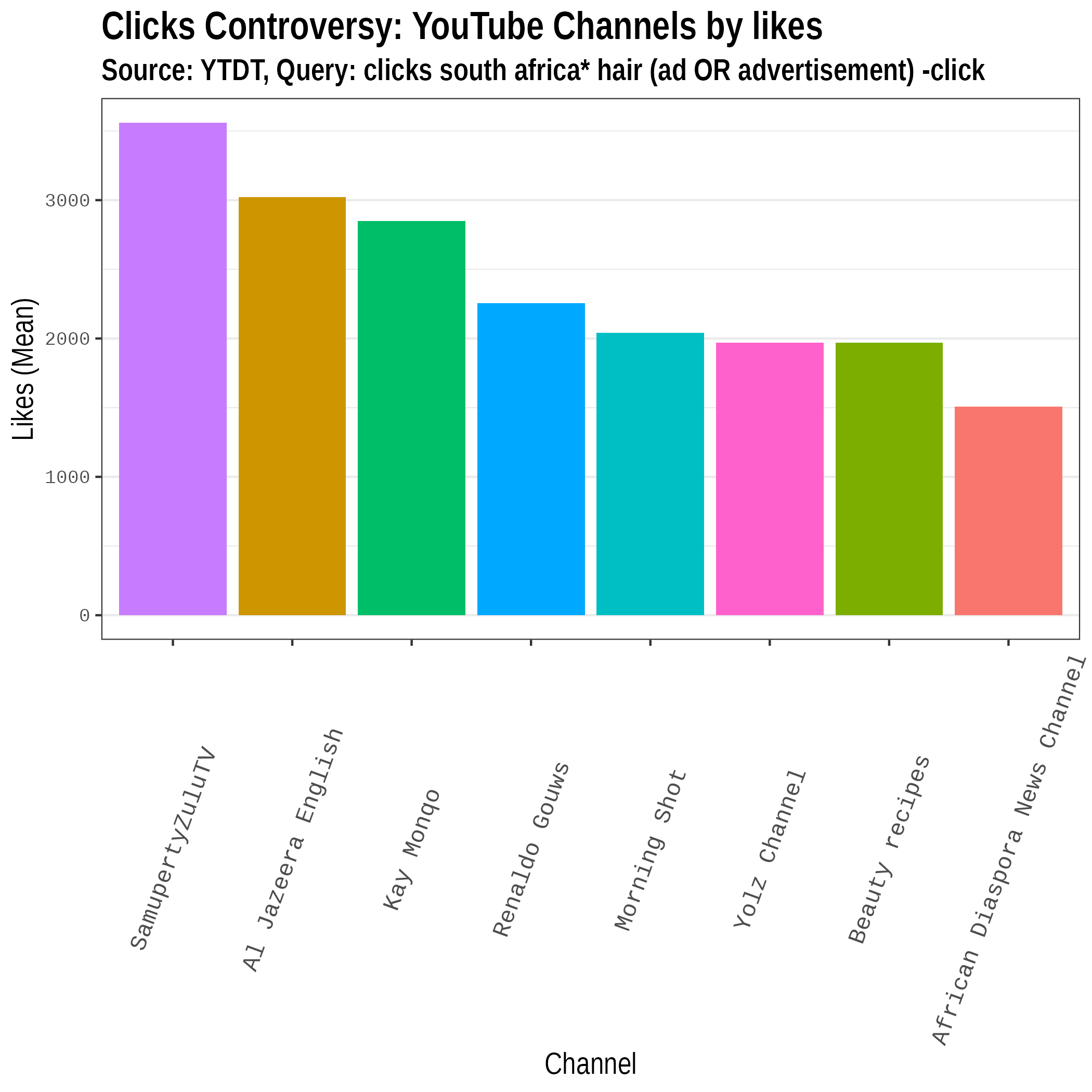
Most “liked” channels
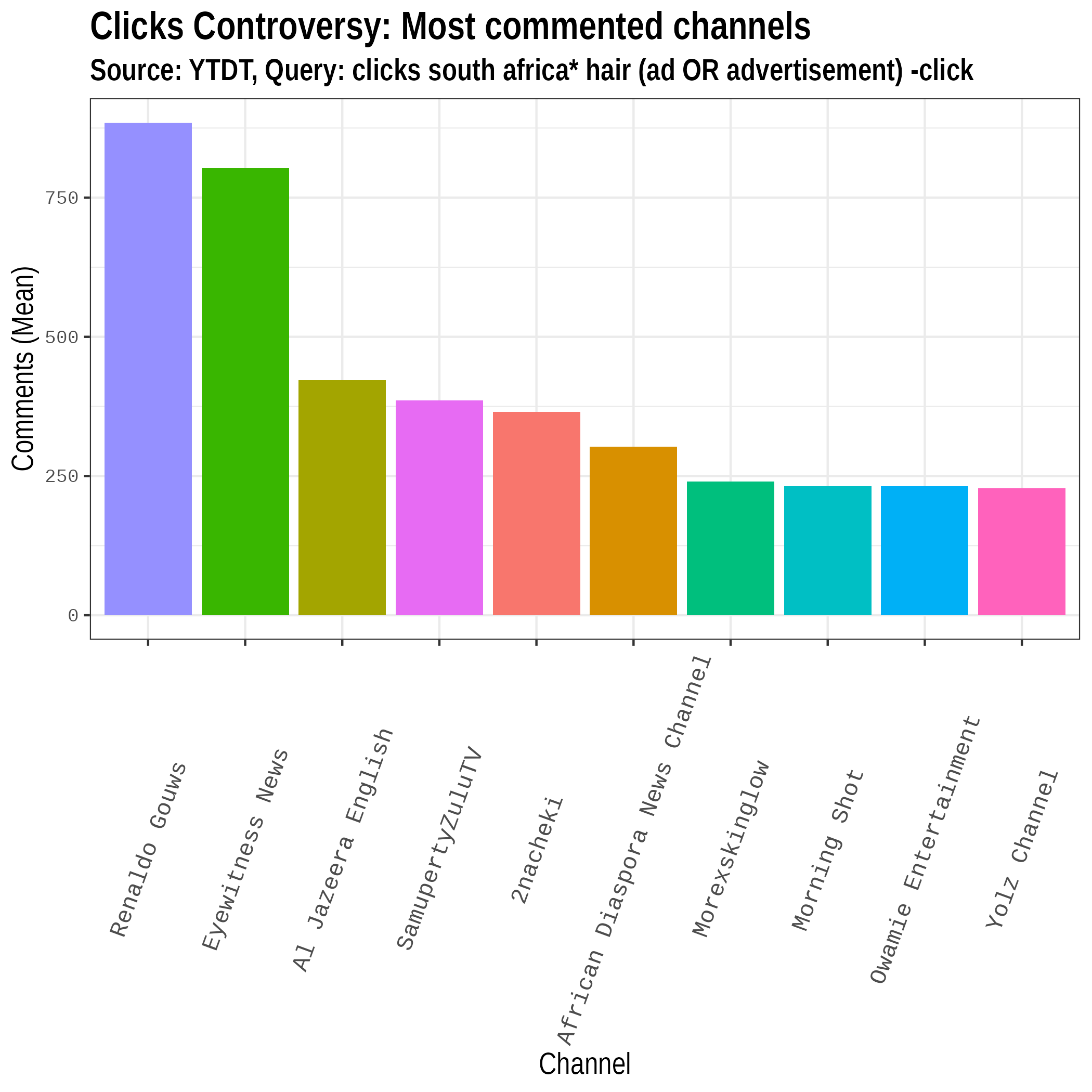
Most commented channels
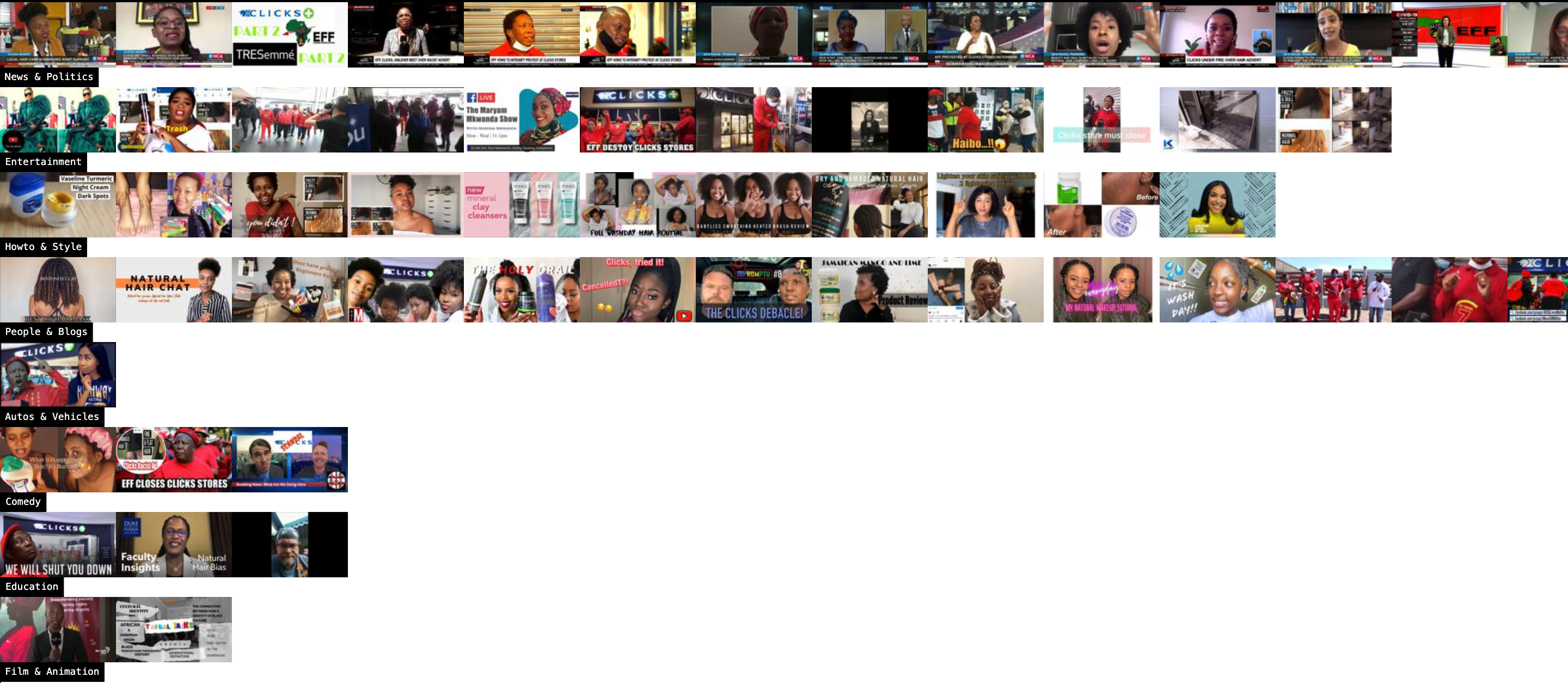
Videos by category
Collocation
Collocation
The above-chance frequent co-occurrence of two words within a pre-determined span, usually five words on either side of the word under investigation (the node) (see Sinclair, 1991)
The statistical calculation of collocation is based on three measures:
The frequency of the word/node,
The frequency of the collocates, and
The frequency of the collocation.
Video Descriptions
Frequencies
eff malema julius stores black natural advert protest also use
181 115 103 71 60 54 51 51 42 40 
Stopwords
Context-specific
- Languages
- Search queries (e.g. Clicks, advertisement)
- Discourses
Stopwords in Voyant Tools
Use Voyant Tools to add stopwords to the Clicks Corpus.
Collocations
We will explore collocation in the descriptions of the videos sample (n=200)
| collocation | count |
|---|---|
| julius malema | 94 |
| eff protest | 21 |
| across country | 13 |
| dry damaged | 14 |
| controversial advert | 11 |
| health beauty | 8 |
| stores across | 12 |
| black women | 10 |
| EFF members | 14 |
| racist advert | 9 |
| comment share | 6 |
| seed oil | 6 |
| face pack | 18 |
| following controversial | 5 |
| beauty retailer | 5 |
| thank much | 5 |
| tune afrika | 8 |
| subscribing liking | 5 |
| today eff | 7 |
| fine flat | 6 |
Starting points - Stopwords
- Experiment with a suitable Stoplist for the Clicks Video Descriptions in Voyant Tools - with Stop List
Concordance
Concordance
A list of all the occurrences of a particular search term in a corpus, presented within the
context that they occur in, usually a few words to the left and right of the search term.Co-textallows analyst to infer (some) context
Context allows us to address qualitative research questions
KWIC
- Concordance is also known as “key word in context” or KWIC analysis
Concordance for MCQ
- Wordtree by Jason Davies
- Multilingual concordancer by Voyant Tools
- Rivonia Speech in Voyant Tools - with Stop List
- Clicks Video Descriptions in Voyant Tools - with Stop List
- Clicks Comments (Random sample) in Voyant Tools - with Stop List
How-to Videos
- Please see Amathuba Lecture Slides tab for “How-to” video with demos of how to use Voyant Tools concordancer
Voyant Tools “How To” video on Amathuba
Starting points - Concordance
- Compare “controversial advert” to “racist advert” in the Clicks Video Descriptions in Voyant Tools - with Stop List
- Compare “controversial” to “racist” in the Clicks Comments (Random sample) in Voyant Tools - with Stop List
- Compare concordances of “beautiful” and “ugly” and “dark” and “light” in the Clicks Comments (Random sample) in Voyant Tools - with Stop List
Clicks data
You can download both datasets from the links below:
- Video description text (1964)
- Comments text (1994)
Keyness
What is keyness?
“Keyness is defined as the statistically significantly higher frequency of particular words or clusters in the corpus under analysis in comparison with another corpus, either a general reference corpus, or a comparable specialised corpus. Its purpose is to point towards the”aboutness” of a text or homogeneous corpus (Scott, 1999), that is, its topic, and the central elements of its content.”
Research and keyness
Keyness allows us to address comparative research questions such as:
- What kinds of discourse are associated with News and Youtuber/influencer channels respectively?
Comparing keyness across categories
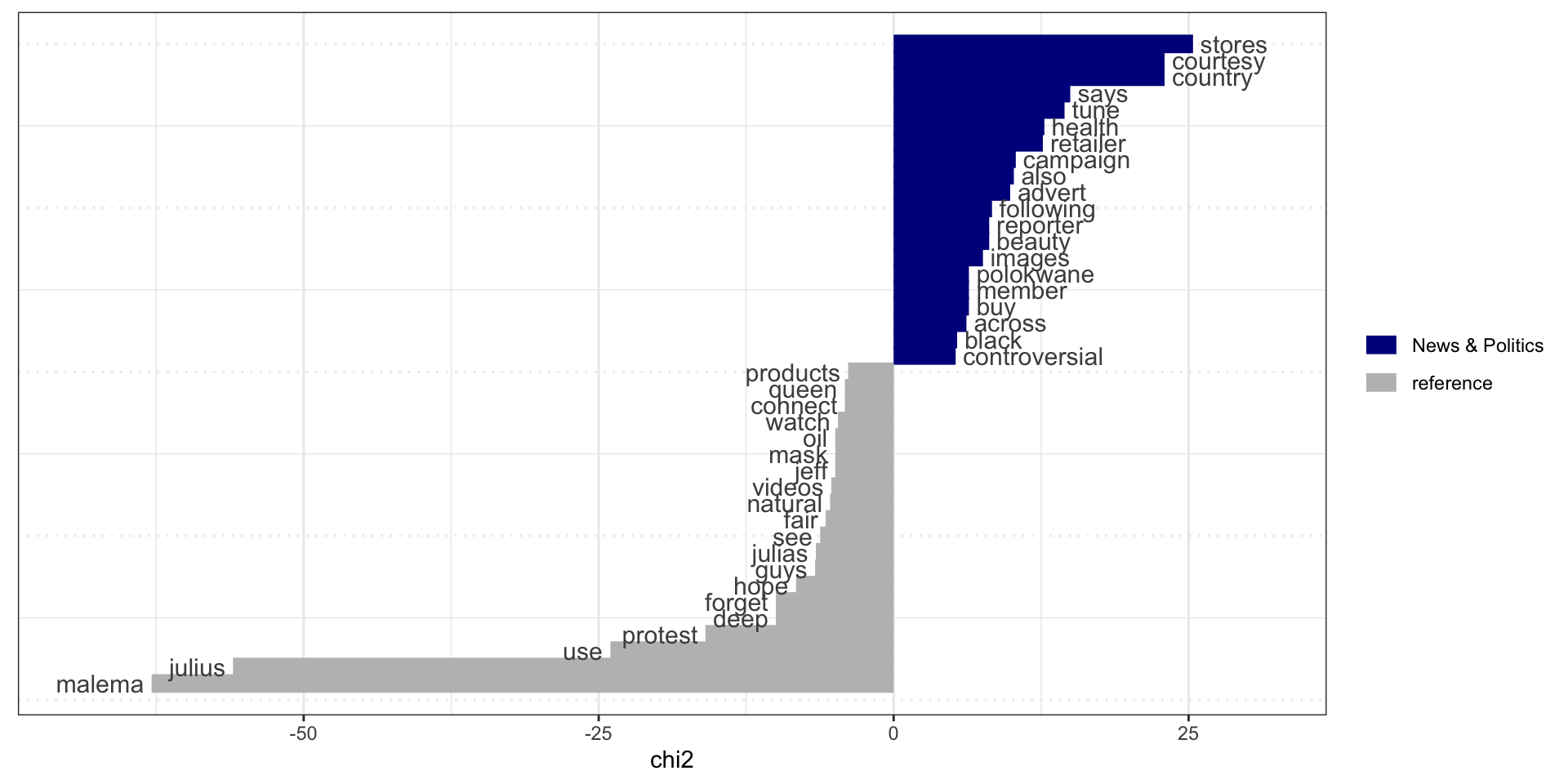
Conclusion
Limits of “co-text”
Tools such as collocation, concordance and keyness allow us to investigate textual “co-text” and infer some contextual features.
Situated meanings are elusive but broader textual patterns can be distinguished.
Multimodality is a central aspect of context. Multimodal meanings are challenging to access with current tools.
Note
TF-IDF
TF-IDF (Term Frequency-Inverse Document Frequency) is a commonly used measure of keyness.
How important is a word is within a document relative to a collection of documents (corpus)?
Can help highlight key words that distinguish a document while reducing the importance of commonly used words that appear in most documents.
- Term Frequency (TF) - how frequently a word appears in a document
- Inverse Document Frequency(IDF) - how unique that word is across all documents in the corpus.
Social media corpus
In this lecture we’ll be investigating a dataset of 200 Youtube videos focused on the controversy about a Tresseme advert posted on the Clicks website in September 2020.
The text-based corpus includes: